Tiny ML case: Smart Shipment with Arduino IDE

Shipment systems are one of the fields where AI and machine learning can be very useful since data-driven algorithms offer a great opportunity to efficiently collect and analyze shipment data and track package safety in real time.
This project showcases how customers can easily track the status of transported packages to monitor if they are moving, staying in the same place, impacted, thrown, picked up, placed in the wrong position, etc.
Project Overview
The project is based on two components: the Internet of Things (IoT) and Artificial Intelligence (AI). The AI part consists in building and embedding a tinyML model in a microcontroller using Neuton to be able to identify the status of a package, while the IoT is used for timely sending of the status to a cloud server accessed via a web app.
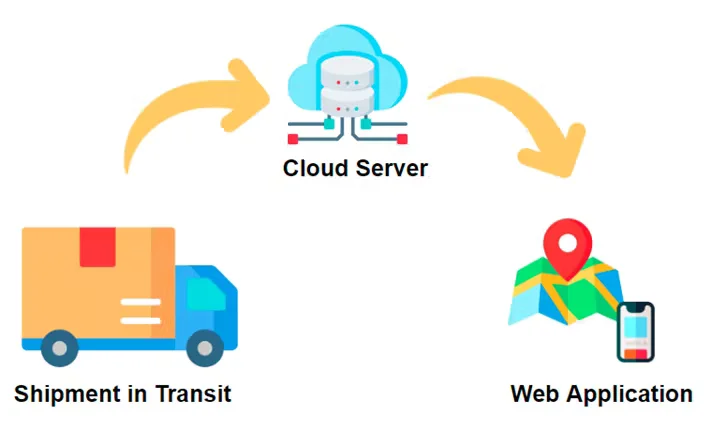
Each package/shipment has a microcontroller (MCU), and each MCU has an embedded TinyML model in it. The inferencing occurs on the device and the result is transmitted to the server as a simple text stream.
Running a machine learning model directly on the device, instead of the cloud, allows you to significantly reduce the amount of information sent to the cloud. This means that we send only triggers of the changed state to the cloud, instead of constantly sending data to determine the state (thus reducing the overall cost of the project).
Requirements
The required hardware and software to build this project include:
Hardware Requirements:
- Processor: MCU
- Sensor: Accelerometer, Gyroscope
- Communication: WiFi, GSM, NB-IoT/LTE-M, LoRa
Software Requirements:
- Neuton.ai
- Arduino IDE
- Visual Studio Code
- MQTT Broker
Choosing an MCU
Since TinyML models, built with Neuton, demonstrate compact size and high accuracy, they are deployable on all types of MCUs, even memory-constrained ones. For this project, we use an M5Stack Core 2 AWS IoT Kit, which is an ESP32-based MCU. It is built in a 6-axis IMU (Inertial Measurement Unit) Unit MPU6886. The MPU6886 is a 6-axis attitude sensor with a 3-axis gravity accelerometer and a 3-axis gyroscope, which can calculate tilt angle and acceleration in real time.
Workflow
The project workflow consists of two stages, model building and model execution, which are visualized on the following diagram:
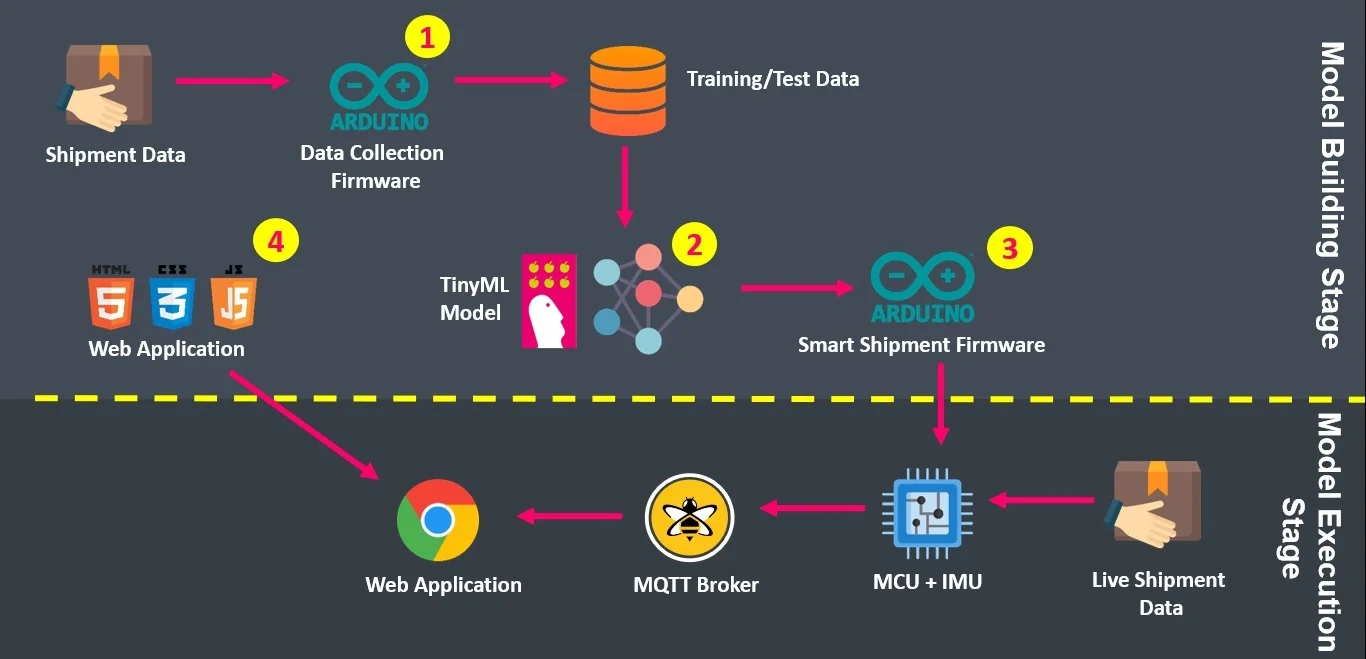
The Model Building Stage includes four steps:
- Step 1: Collect the data using Data Collection Firmware and prepare the Training/Test Data.
- Step 2: Build the TinyML model using Neuton and download the TinyML model as C Source Library.
- Step 3: Program smart shipment firmware using the downloaded C Library, which is a TinyML Model, program the firmware and embed it on the device.
- Step 4: Program the web app using the PAHO MQTT jаvascript library.
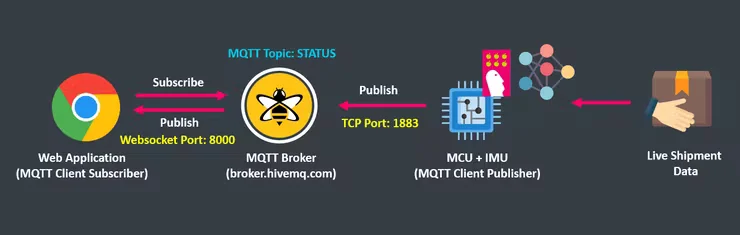
In the Model Execution stage, both the Smart Shipment Firmware (MQTT Client Publisher) and Web App (MQTT Client Subscriber) communicate with each other via the MQTT broker. The following diagram shows this communication process in detail:
TinyML Model Creation
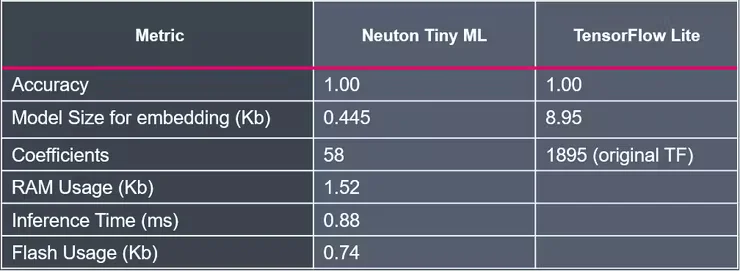
One of the most critical steps of any AI-based project is building an ML model. The challenge is not only to build the most accurate model, but to get the ideal combination of maximum accuracy and minimum size, so that the model can be embedded in any low-power MCU. This challenge is easily solved by Neuton, as it automatically builds the tiniest model with 100% accuracy.
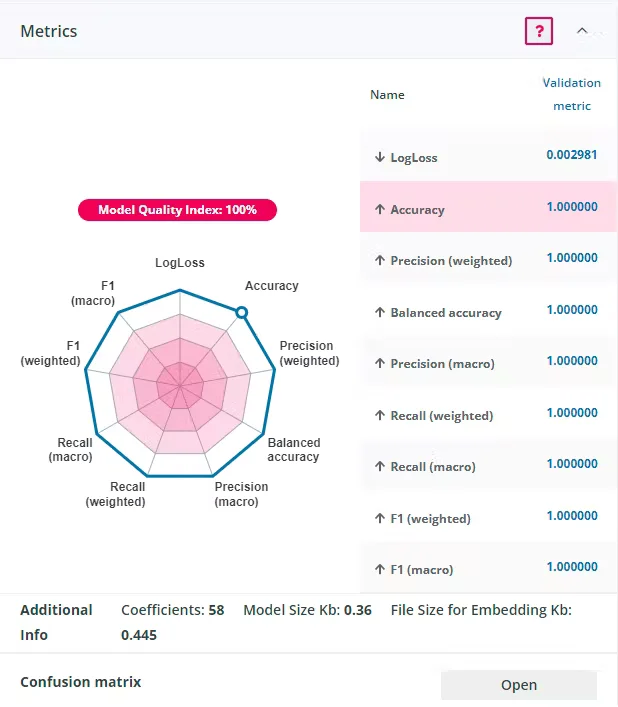
The embedding size of the TinyML model developed with Neuton is only 0,445 Kb, which is 20 times smaller in size than a 8,95 Kb model built with TensorFlow Lite.
Check out how the final solution works:
This case is developed and launched by Timothy Malche, an assistant professor in the Computer Application Department at Manipal University Jaipur and Neuton Ambassador. Check out the full write-up
Want to create your own project? Try Neuton for free right now!