Task type & Metric
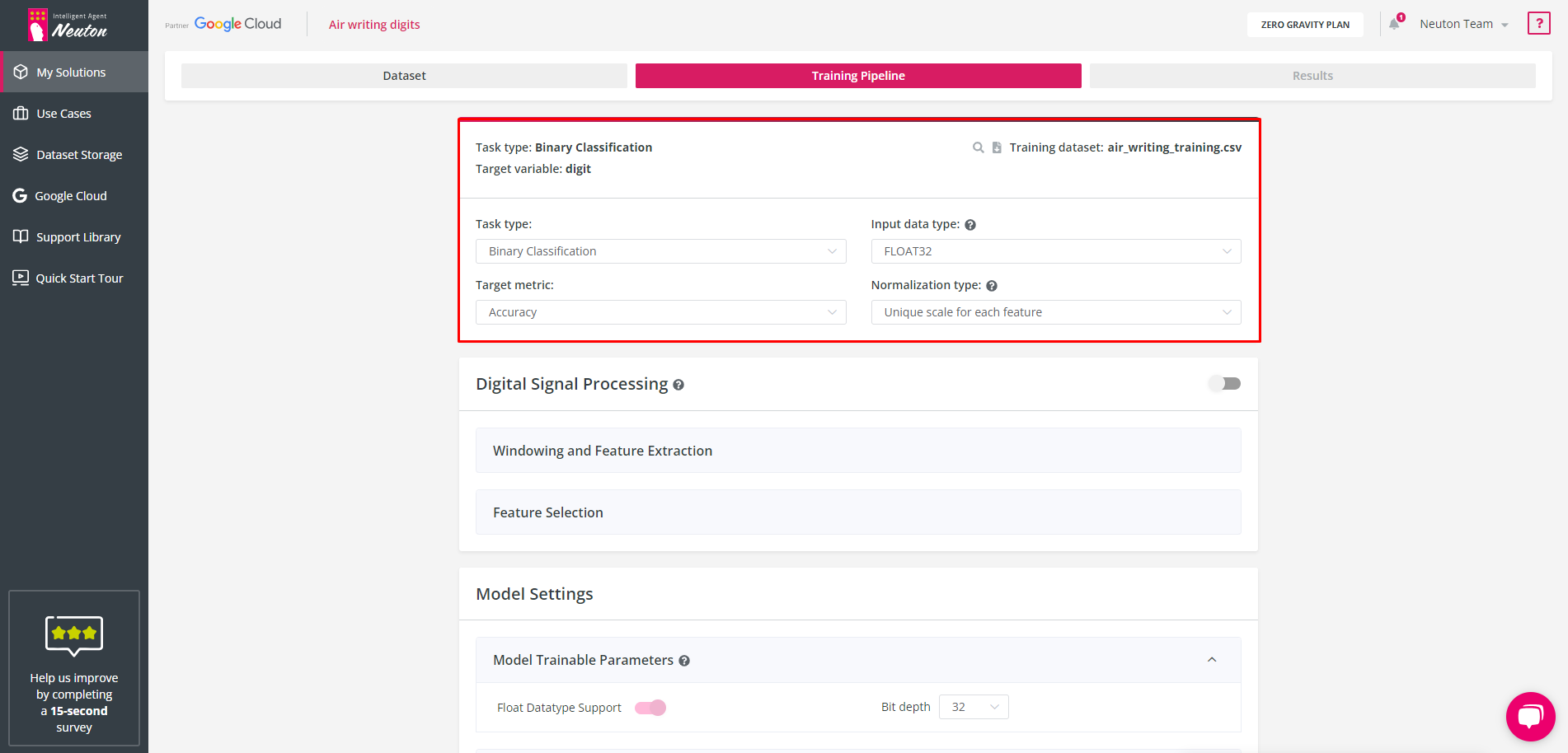
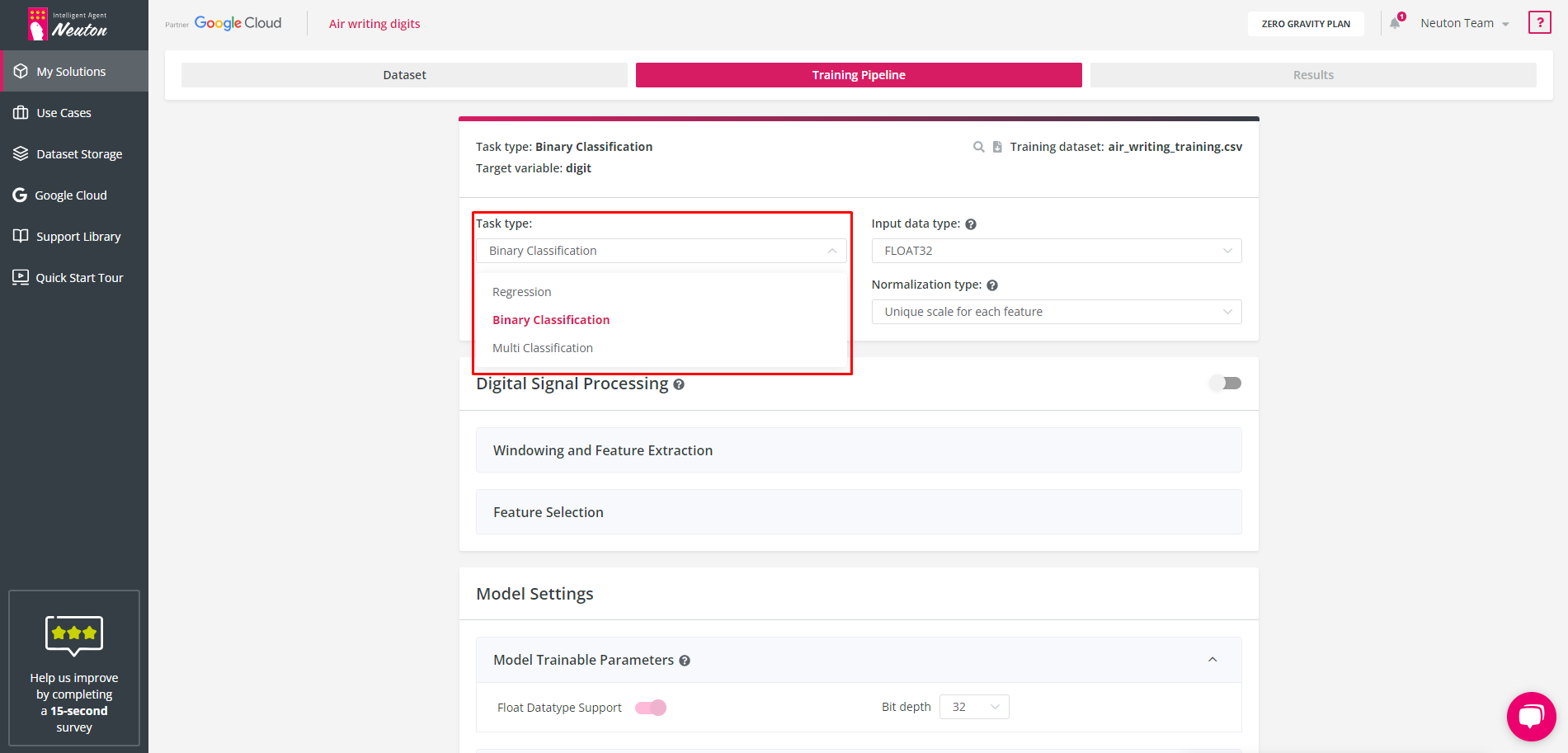
Task Type
Select the task type: Regression / Binary Classification / Multiclass Classification and the metric to measure model quality. Neuton can automatically detect a task type based on the target variable values, but you can also specify this parameter manually.
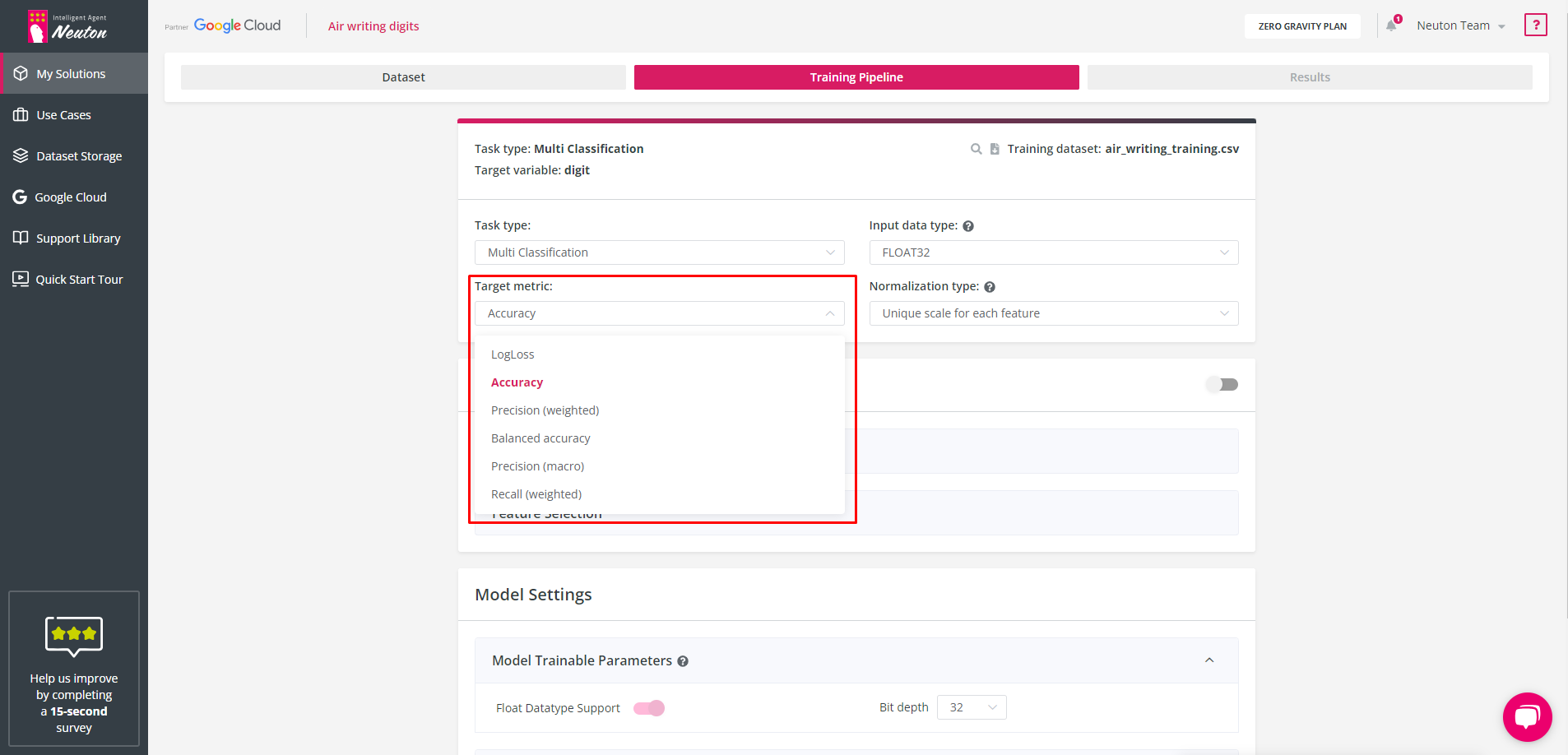
For Binary and Multiclass classification task types, the default value of the target metric is Accuracy, for the Regression task type the default target metric is RMSE (Root mean squared error, for more information please refer to "
Glossary").
Target Metric
During the training phase, the platform will measure the validation metric at each training iteration using a 10-fold cross-validation approach. Neuton has a built-in patented feature to prevent overfitting (overtraining) which stops training right before overfitting starts to occur. If the holdout validation dataset was specified final metrics will be calculated for it.
Regardless of the target metric you have chosen, the platform will count all the metrics available on the platform for this type of task. Detailed metrics descriptions are available in the Glossary.
Input Data Type
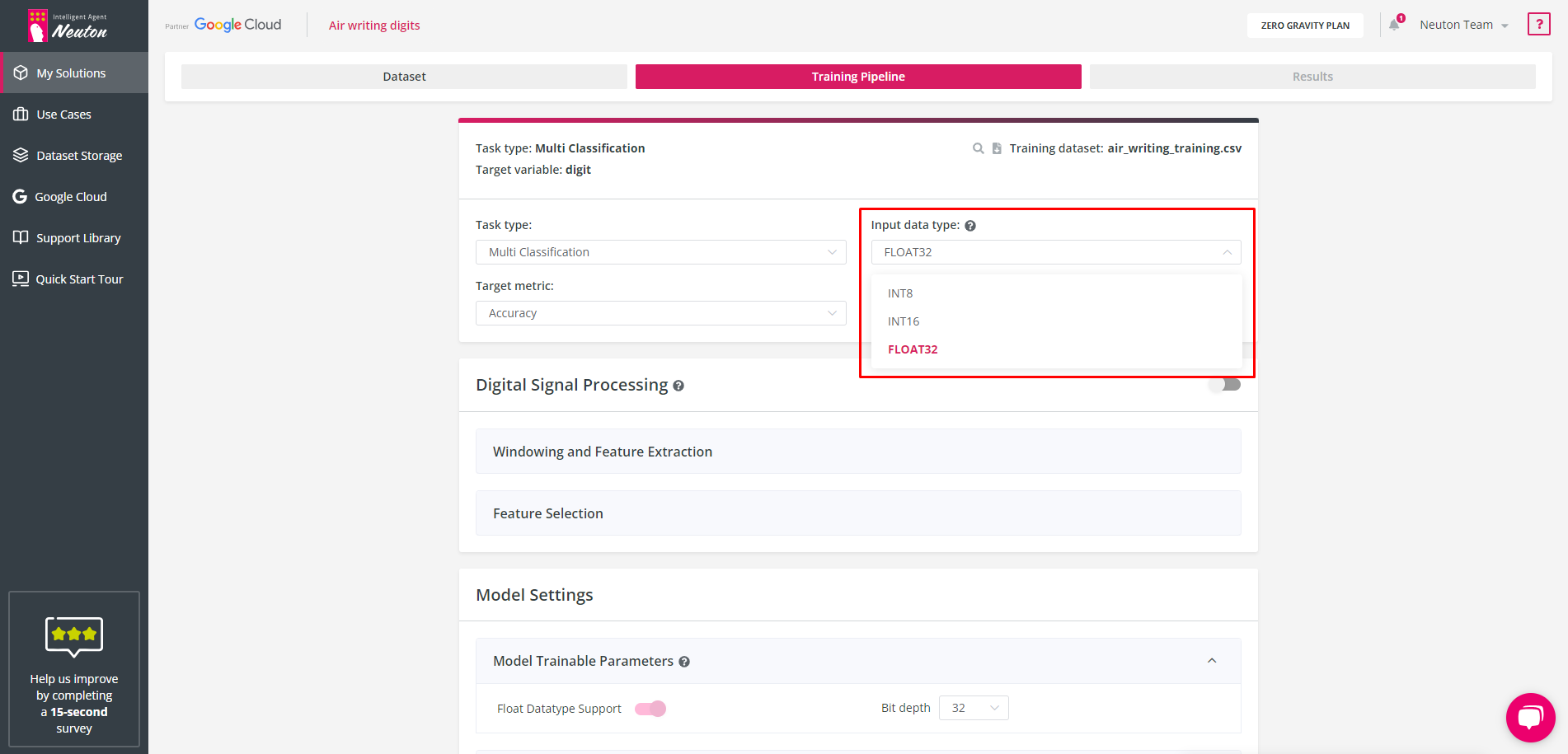
Input Data Type
Select input data type according to the data type of all features in the training dataset. Keep in mind that you only need to choose one data type for the entire dataset. For example, if you have a dataset with three features and two of them are represented as INT16 while the third one is represented as FLOAT32, you should choose FLOAT32 as the data type for the entire dataset. The platform automatically determines the data type based on the logic discussed above. However, if the data type is not determined correctly, you can change it manually. Input data type specification allows you to optimize the preprocessing operation and reduce SRAM and Flash usage on the device and inference time. The data of the same type must be used for prediction. Neuton supports the following input data types: INT8, INT16, and FLOAT32.
It is important to select the correct data type as incorrect selection of input data type may cause target metric degradation or total footprint increase.
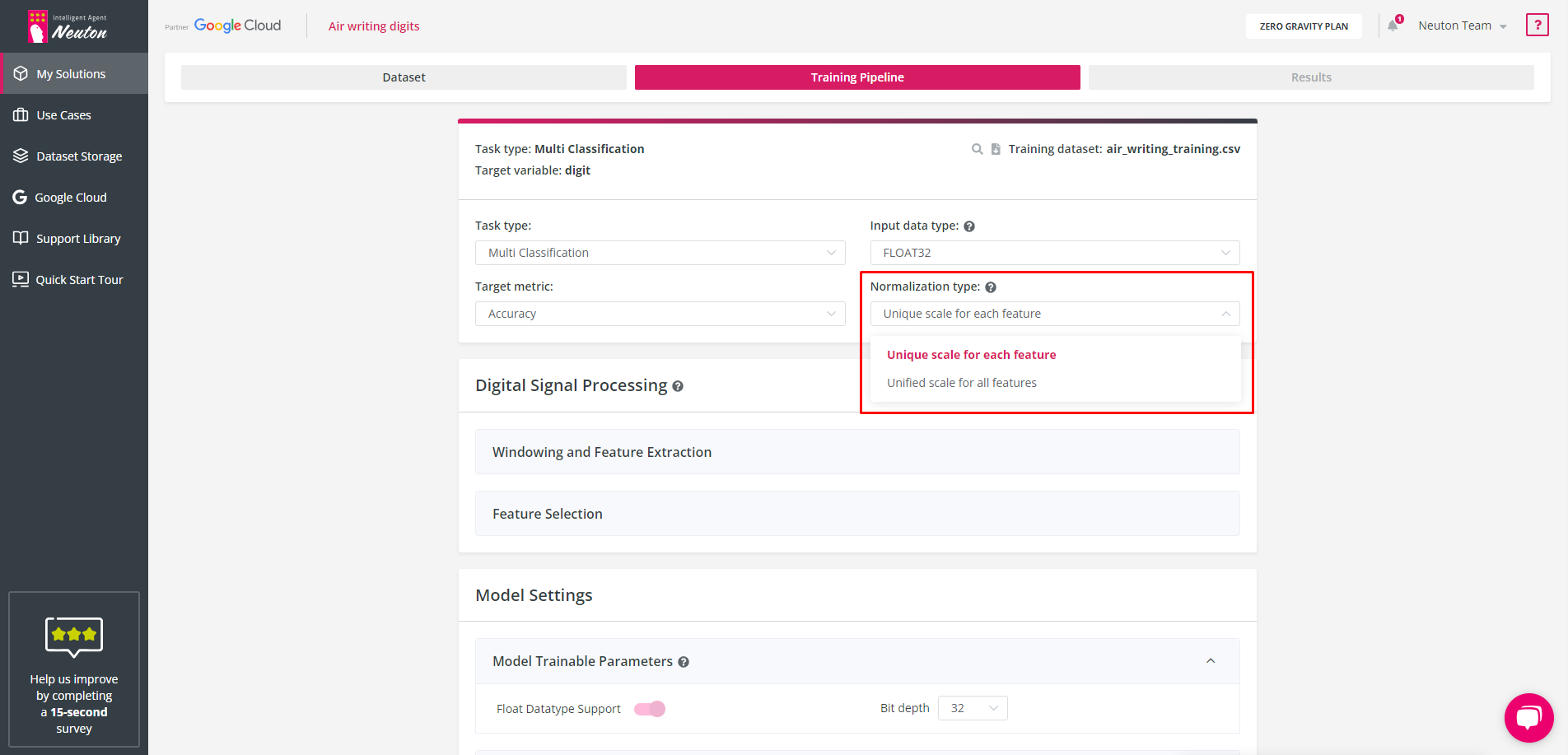
Normalization type
![]()
Normalization Type
This option allows you to select one of two scaling types for your dataset: “Unique scale for each feature” or “Unified scale for all features”. For model training normalization is used, unique scaling for each feature may increase model predictive power as well as model footprint, there as unified scaling may decrease model footprint. Everything depends on your dаta: it is better to use a “Unified scale for all features” when all values are on the same scale for all features.
If your data requires additional processing and you enable the
digital signal processing option, then the normalization type will be the following: >
Features created in Feature Extraction options will be normalized within its own scale.
Raw data will be normalized within the scale of each variable/axis.