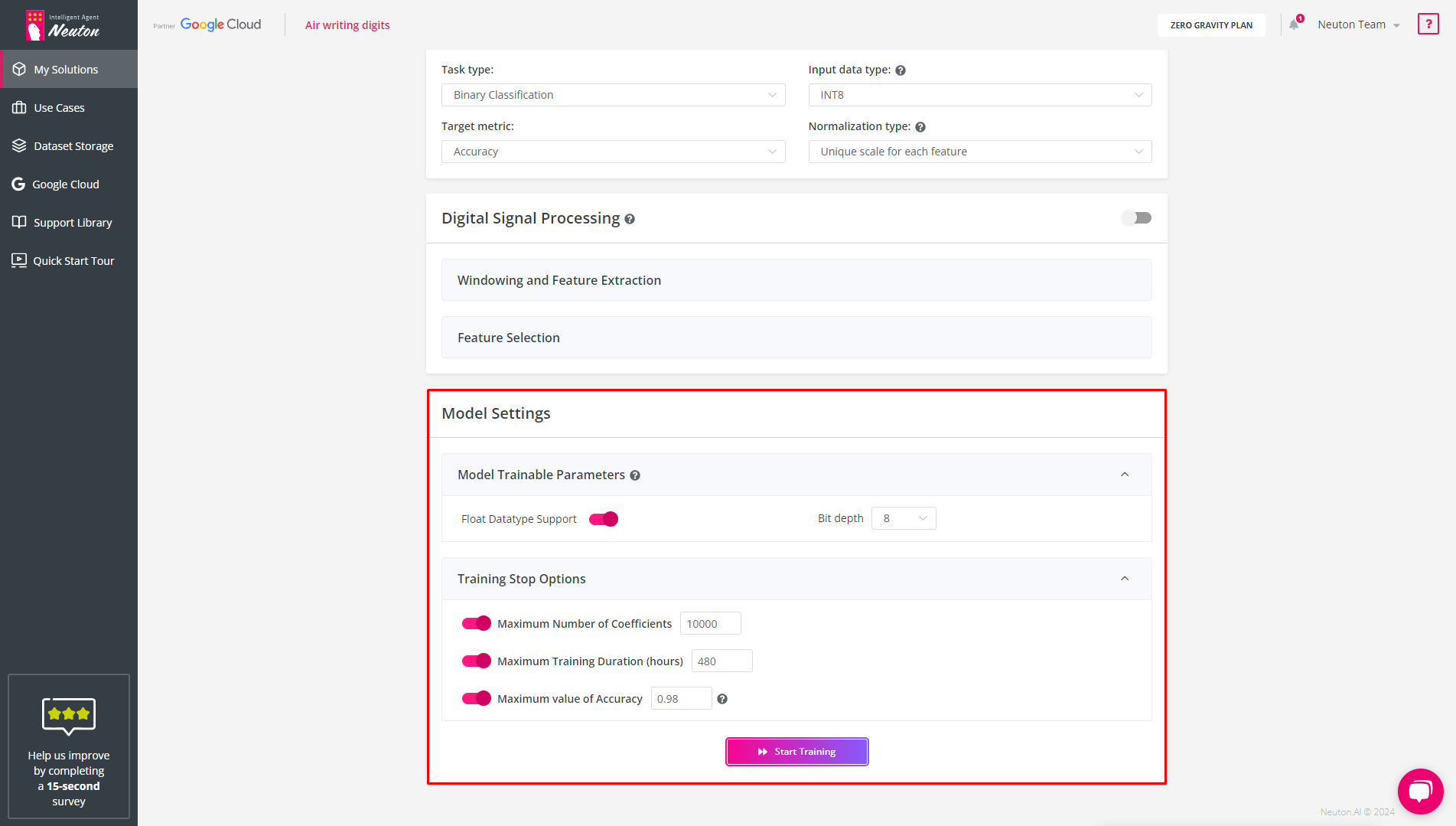
Model Trainable Parameters
Select parameters in which calculations will be performed inside the model. If you plan to optimize resource usage, choose the 8-bit coefficient storage format. With Float Datatype Support enabled, you can build models that support operations with floats.
By default, the model calculation settings correspond to the type of train data you have selected. However, you can configure the calculation parameters of the model depending on the problem to be solved.
For 8 and 16-bit storage of coefficients, calculations are available both in floats and in integers. For 32-bit storage – only in floats.
Maximum Number of Coefficients
Neuton models are very small by default, but you may still limit the number of coefficients if necessary. By default, the number of coefficients is unlimited.
Maximum Training Duration (hours)
For optimal use of the infrastructure, you can limit the model training time. Upon reaching the time limit during training, the platform will stop the training and save the best model.
Maximum Value of Accuracy
Training will stop upon reaching the specified metric value. Depending on the metric, the resulting Value may be lower or higher if the model cannot achieve the specified accuracy.
![]()
Model Settings
After the training parameters are defined click “Start training” to start the training process.
Model training may take from several minutes to several hours depending on the dataset size. For your convenience, you may leave your phone number and be notified about the end of training via text messages.