Neuton, our unique neural network framework, natively creates incredibly compact and accurate models that can easily be deployed into your firmware project using an automatically generated archive with a C library.
The library is written in accordance with the C99 standard, so it is universal and does not have strict requirements for the hardware. The ability to use the library depends mainly on the amount of memory available for its operation.
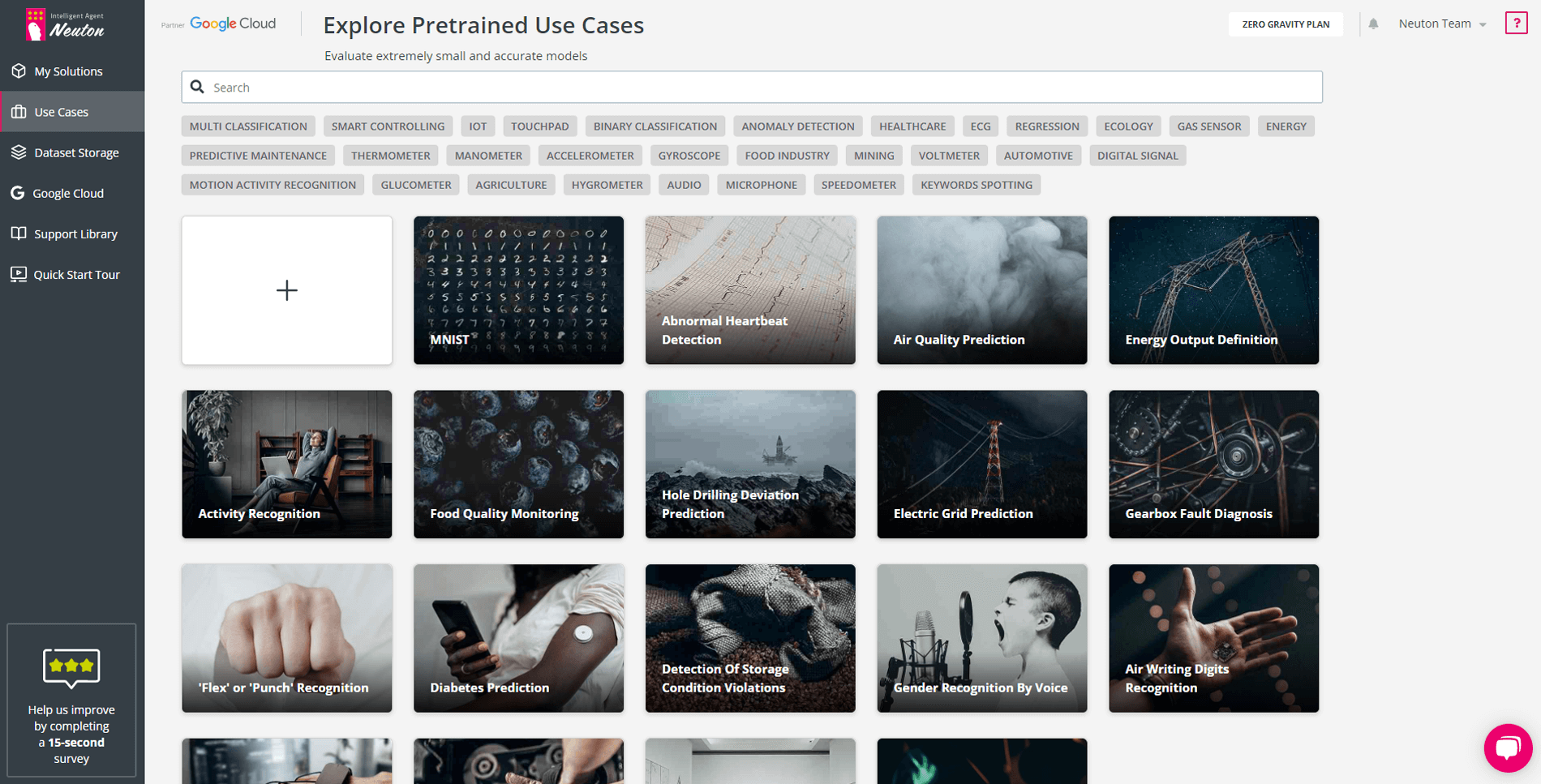
How to integrate Neuton into your firmware project
Neuton folder structure
There are only two folders that should be added to your project for integrating Neuton:
Also, you should add folder where ./neuton_generated is located and ./neuton/include folder to your project INCLUDE paths.
Use Neuton in your project
First of all, you need to include the main header file of Neuton:
#include <neuton/neuton.h>
For making an inference with Neuton, there are only 3 functions that you should use:
neuton_nn_setup - Set up the internal components of Neuton, should be called first and once;neuton_nn_feed_inputs - Feed and prepare live input features for model inference;neuton_nn_run_inference - Run live input features into a Neuton machine learning algorithm (or “ML model”) to calculate an output;
Feed input values
Make an array with model raw input features(signal data). Inputs count and order should be the same as in the training dataset.
neuton_input_t raw_inputs[] = {
raw_input_0,
raw_input_1,
raw_input_N
};
Pass this input array to the neuton_nn_feed_inputs function.
neuton_nn_setup();
neuton_inference_input_t* p_input = neuton_nn_feed_inputs(raw_inputs, neuton_nn_uniq_inputs_num());
if (p_input != NULL)
{
}
In case the Neuton solution needs to collect a data window, you can use the following sample-by-sample feed algorithm:
neuton_nn_setup()
for (size_t i = 0
{
neuton_inference_input_t* p_input = neuton_nn_feed_inputs(raw_inputs, neuton_nn_uniq_inputs_num())
if (p_input != NULL)
{
//make inference
break
}
raw_inputs += neuton_nn_uniq_inputs_num()
}
Or feed all input samples at once:
neuton_nn_setup();
neuton_inference_input_t* p_input;
p_input = neuton_nn_feed_inputs(raw_inputs, neuton_nn_uniq_inputs_num() * neuton_nn_input_window_size());
if (p_input != NULL)
{
}
Run Inference
When input buffer is ready for running inference, you should call neuton_nn_run_inference with three arguments:
p_input - Input features for model inference, obtained from @ref neuton_nn_feed_inputs() API callp_index - Index of predicted target(class) with highest probability;pp_outputs - Pointer to pointer to the internal buffer with all predicted outputs, contains predicted target variable (for regression task) or probabilities of each class (binary/multi classification tasks).
Wrapping everything together
/** Setup Neuton */
neuton_nn_setup()
/** Feed and prepare raw inputs for the model inference */
neuton_inference_input_t* p_input
p_input = neuton_nn_feed_inputs(raw_inputs, neuton_nn_uniq_inputs_num() * neuton_nn_input_window_size());
/** Run inference */
if (p_input)
{
neuton_u16_t predicted_target
neuton_output_t* probabilities
neuton_i16_t outputs_num = neuton_nn_run_inference(p_input, &predicted_target, &probabilities)
if (outputs_num > 0)
{
printf("Predicted target %d with probability %f\r\n", predicted_target, probabilities[predicted_target])
printf("All probabilities:\r\n")
for (size_t i = 0
printf("%f," probabilities[i])
}
}
Map predicted results on the required values (for Classification task type)
Inference results are encoded (0…n). For mapping on your classes, use dictionaries binary_target_dict_csv.csv / multi_target_dict_csv.csv.
Additional solution information API
You can use the following API to get solution information:
neuton_nn_solution_id_str - Get solution ID in string format;neuton_nn_uniq_inputs_num - Get number of unique input features on which the model was trained;neuton_nn_input_window_size - Get input features window size in feature samples(vectors);neuton_nn_model_neurons_num - Get number of model neurons;neuton_nn_model_weights_num - Get number of model weights;neuton_nn_model_outputs_num - Get number of model outputs (predicted targets);neuton_nn_model_task - Get model task : NEUTON_NN_TASK_MULT_CLASS, NEUTON_NN_TASK_BIN_CLASS, NEUTON_NN_TASK_REGRESSIONneuton_nn_model_size - Get model size in bytes (flash usage)neuton_nn_model_bitdepth - Get model bit depth (8/16/32 bit)neuton_nn_input_scaling - Get solution input scaling type: NEUTON_NN_INPUT_SCALING_UNIFIED, NEUTON_NN_INPUT_SCALING_UNIQUE
Neuton, our unique neural network framework, natively creates incredibly compact and accurate models that can easily be deployed into your firmware project using an automatically generated archive with a C library.
The library is written in accordance with the C99 standard, so it is universal and does not have strict requirements for the hardware. The ability to use the library depends mainly on the amount of memory available for its operation.
How to integrate Neuton into your firmware project
Neuton folder structure
There are only two folders that should be added to your project for integrating Neuton:
Also, you should add folder where ./neuton_generated is located and ./neuton/include folder to your project INCLUDE paths.
Use Neuton in your project
First of all, you need to include the main header file of Neuton:
#include <neuton/neuton.h>
For making an inference with Neuton, there are only 3 functions that you should use:
neuton_nn_setup - Set up the internal components of Neuton, should be called first and once;neuton_nn_feed_inputs - Feed and prepare live input features for model inference;neuton_nn_run_inference - Run live input features into a Neuton machine learning algorithm (or “ML model”) to calculate an output;
Feed input values
Make an array with model raw input features(signal data). Inputs count and order should be the same as in the training dataset.
neuton_input_t raw_inputs[] = {
raw_input_0,
raw_input_1,
raw_input_N
};
Pass this input array to the neuton_nn_feed_inputs function.
neuton_nn_setup();
neuton_inference_input_t* p_input = neuton_nn_feed_inputs(raw_inputs, neuton_nn_uniq_inputs_num());
if (p_input != NULL)
{
}
In case the Neuton solution needs to collect a data window, you can use the following sample-by-sample feed algorithm:
neuton_nn_setup()
for (size_t i = 0
{
neuton_inference_input_t* p_input = neuton_nn_feed_inputs(raw_inputs, neuton_nn_uniq_inputs_num())
if (p_input != NULL)
{
//make inference
break
}
raw_inputs += neuton_nn_uniq_inputs_num()
}
Or feed all input samples at once:
neuton_nn_setup();
neuton_inference_input_t* p_input;
p_input = neuton_nn_feed_inputs(raw_inputs, neuton_nn_uniq_inputs_num() * neuton_nn_input_window_size());
if (p_input != NULL)
{
}
Run Inference
When input buffer is ready for running inference, you should call neuton_nn_run_inference with three arguments:
p_input - Input features for model inference, obtained from @ref neuton_nn_feed_inputs() API callp_index - Index of predicted target(class) with highest probability;pp_outputs - Pointer to pointer to the internal buffer with all predicted outputs, contains predicted target variable (for regression task) or probabilities of each class (binary/multi classification tasks).
Wrapping everything together
/** Setup Neuton */
neuton_nn_setup()
/** Feed and prepare raw inputs for the model inference */
neuton_inference_input_t* p_input
p_input = neuton_nn_feed_inputs(raw_inputs, neuton_nn_uniq_inputs_num() * neuton_nn_input_window_size());
/** Run inference */
if (p_input)
{
neuton_u16_t predicted_target
neuton_output_t* probabilities
neuton_i16_t outputs_num = neuton_nn_run_inference(p_input, &predicted_target, &probabilities)
if (outputs_num > 0)
{
printf("Predicted target %d with probability %f\r\n", predicted_target, probabilities[predicted_target])
printf("All probabilities:\r\n")
for (size_t i = 0
printf("%f," probabilities[i])
}
}
Map predicted results on the required values (for Classification task type)
Inference results are encoded (0…n). For mapping on your classes, use dictionaries binary_target_dict_csv.csv / multi_target_dict_csv.csv.
Additional solution information API
You can use the following API to get solution information:
neuton_nn_solution_id_str - Get solution ID in string format;neuton_nn_uniq_inputs_num - Get number of unique input features on which the model was trained;neuton_nn_input_window_size - Get input features window size in feature samples(vectors);neuton_nn_model_neurons_num - Get number of model neurons;neuton_nn_model_weights_num - Get number of model weights;neuton_nn_model_outputs_num - Get number of model outputs (predicted targets);neuton_nn_model_task - Get model task : NEUTON_NN_TASK_MULT_CLASS, NEUTON_NN_TASK_BIN_CLASS, NEUTON_NN_TASK_REGRESSIONneuton_nn_model_size - Get model size in bytes (flash usage)neuton_nn_model_bitdepth - Get model bit depth (8/16/32 bit)neuton_nn_input_scaling - Get solution input scaling type: NEUTON_NN_INPUT_SCALING_UNIFIED, NEUTON_NN_INPUT_SCALING_UNIQUE
Audio preprocessing and prediction
Audio preprocessing is not integrated into the common Neuton pipeline, but we provide a set of algorithms and an external audio frontend for possible integration. You can find audio Keyword Spotting frontend in the pipeline/kws/neuton_kws_frontend.h.
Here is a code example of audio preprocessing with Neuton:
#include <neuton/neuton.h>
#include <neuton_generated/neuton_user_data_prep_config.h>
#include <pipeline/kws/neuton_kws_frontend.h>
#include <string.h>
static neuton_kws_frontend_ctx_t* kws_frontend = NULL;
static void on_spectrum_ready(void* p_ctx, neuton_f32_t* p_spectrum)
{
neuton_kws_frontend_ctx_t* p_kws = (neuton_kws_frontend_ctx_t*)p_ctx;
neuton_inference_input_t* p_input;
p_input = neuton_nn_feed_inputs(p_spectrum, p_kws->melspectr.freq_bands * p_kws->melspectr.time_bands);
if (p_input != NULL)
{
neuton_u16_t predicted_target;
neuton_output_t* probabilities;
neuton_i16_t outputs_num = neuton_nn_run_inference(p_input, &predicted_target, &probabilities);
if (outputs_num > 0)
{
printf("Predicted class %d with probability %f\r\n", predicted_target, probabilities[predicted_target]);
}
}
}
bool init_audio_frontend(void)
{
kws_frontend = malloc(sizeof(neuton_kws_frontend_ctx_t));
neuton_status_t res = neuton_kws_frontend_init(kws_frontend, NEUTON_DSP_AUDIO_WINDOW_LENGTH,
NEUTON_DSP_AUDIO_WINDOW_HOP,
NEUTON_DSP_AUDIO_SAMPLING_RATE_HZ,
NEUTON_DSP_MELSPECTROGRAM_TIME_BANDS,
NEUTON_DSP_MELSPECTROGRAM_FREQ_BANDS,
0, NULL, on_spectrum_ready, kws_frontend);
return (res == NEUTON_STATUS_SUCCESS);
}
void feed_audio_samples(const float* p_audio_samples, size_t samples_num)
{
neuton_kws_frontend_process(kws_frontend, p_audio_samples, samples_num);
}